
Sort by
Block Pattern: Slim Fit
Topic Modeling
- Topic modeling is used to classify documents against a static list of topics, a.k.a. Information Architecture.
- How it can be used:
- Implement simple Item ranking algorithms to present related articles.
- If a user reads an article, then we can run a retargeting campaign and send out Push Notifications that include the next related article published on the topic.
- Finally, when combined with Editorial Analytics to guide editors on what to cover next.
- Hard problem
- It isn’t straight forward. Even algorithms at BigTech platform like Twitter miss out on the nuance. Let’s look at four instances of how this algorithm performs on Twitter.com. In each of the four examples, the topic modeling algorithm chooses a topic that isn’t what a human would have chosen.
- A tweet on the acquisition of News Product Kinzen by Spotify is classified under Backstage.

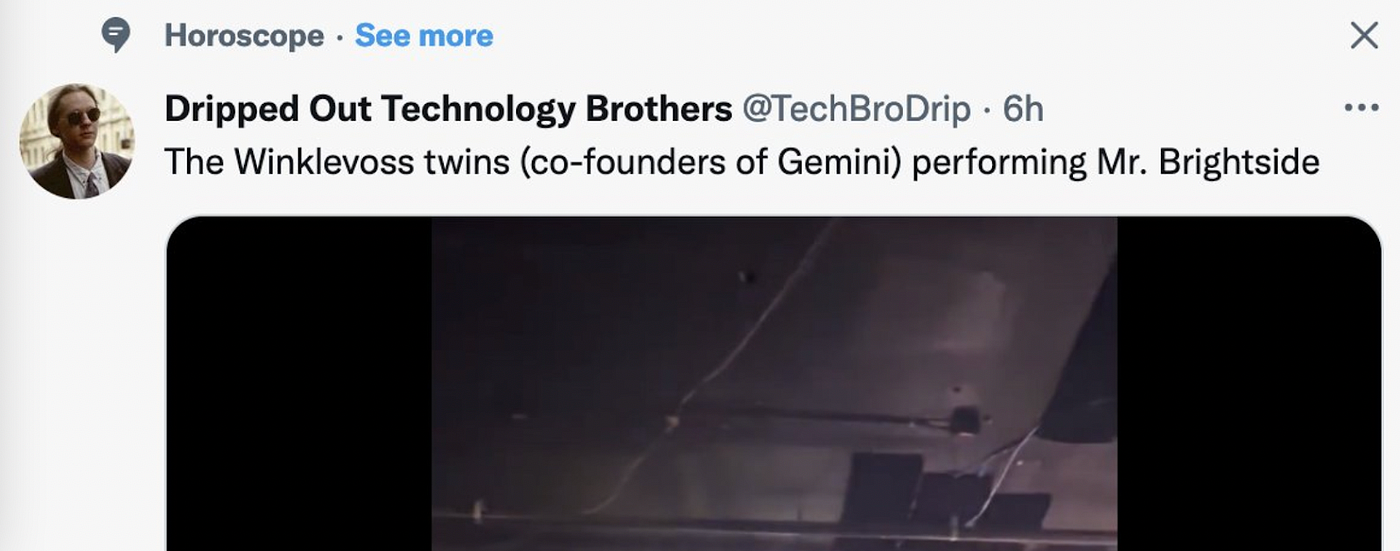
- A tweet on Winklevoss twins is classified under the topic Horoscope possibly because their company is called Gemini.
- Here’s a tweet on the need for star cricketers to go back to domestic cricket when they are out of form. Even though the tweet mentions five cricketers, the Twitter algorithm classified it as only under one cricketer.

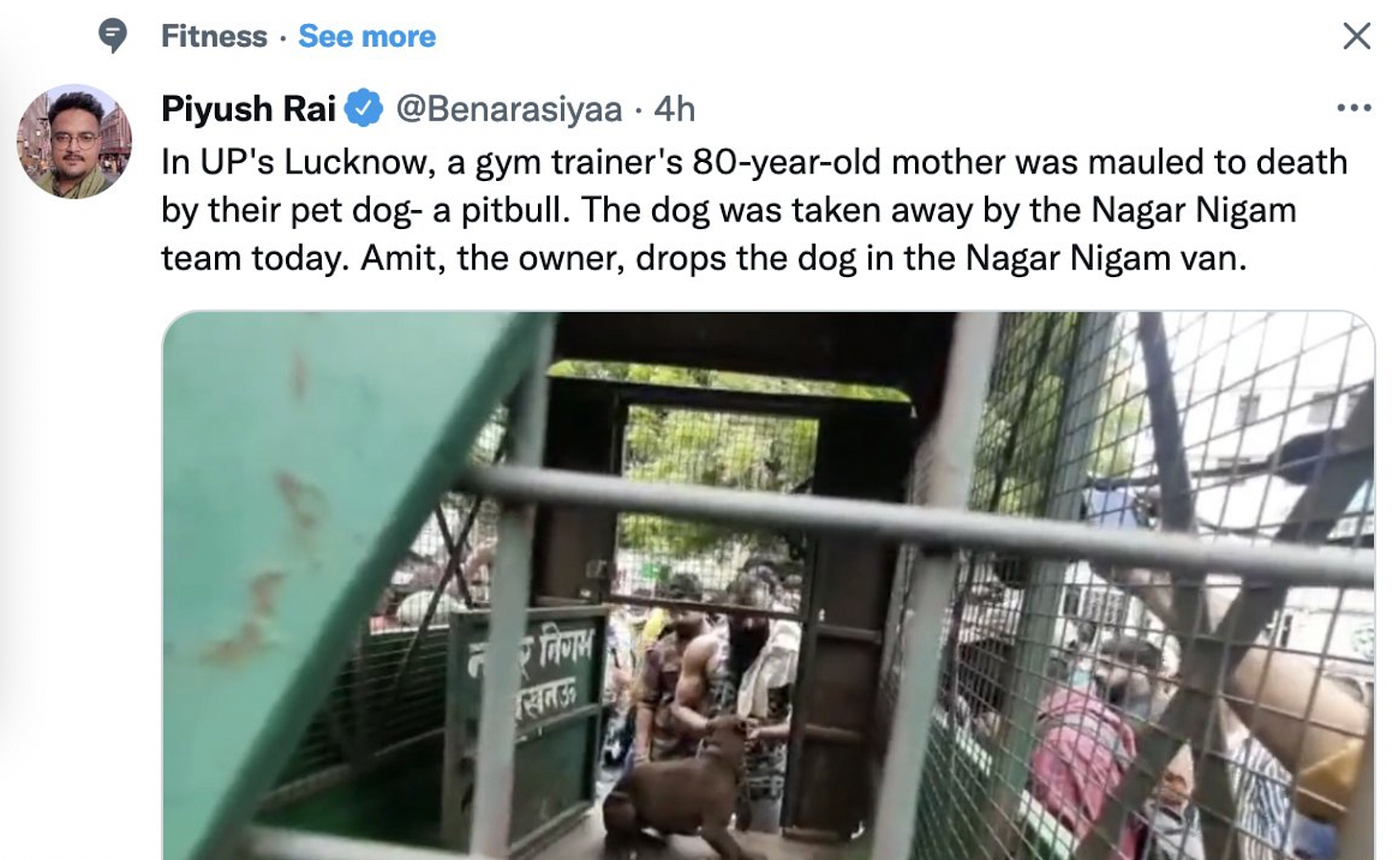
- Finally, here’s a tweet that reports on a news article where a dog mauled down an old lady. Twitter classified it under Fitness.
- Literature review
- There are many open-source topic modeling algorithms: These include Latent Dirichlet Allocation (LDA), Non-negative Matrix Factorization (NMF), BERTopic, Top2Vec, etc. Latent Dirichlet Allocation (LDA) has been the most commonly used algorithm for topic modeling but it faces some serious challenges like sensitivity to stemming and lemmatization and requires a fixed dictionary of topics.
- We explored two methods: Top2Vec and BERTopic.
- What Top2Vec needs: To increase Top2Vec‘s accuracy we need:
- Large training datasets. Generally, the accuracy of Top2Vec is higher if the training dataset is large.
- Yet avoid breadth. The training dataset should be restricted to a few categories instead of the entire news archive.
- Unique nomenclature: Each category should have its own unique vocabulary.
- How Top2Vec works
- We pass the set of articles (documents) that we want to the topic model to Top2Vec. Internally, this is how Top2Vec works:
- Encoding. First, it will generate embedding vectors for each of the articles (documents) and words. We generated document embeddings in batches of 32 articles. Each article is used 40 times (epoch size) to improve the document encoding. To reduce noise, we have used only those keywords that appear in at least 50 documents.
- From sparse to dense. The dimensionality of the embedding vector can be very large. Hence, we reduce the dimensionality using Uniform Manifold Approximation and Projection (UMAP) so that the dense areas in the embedding vector will emerge.
- Identifying clusters (topics) within the vector. To label each dense area as a topic, Top2Vec algorithm uses an unsupervised learning algorithm called HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise).
- Labeling the cluster. In this step, we need to name the cluster (topic). To do this, we find the centroid of each cluster. Words that are closest to the centroid can be used to name the topic.
- Output that Top2Vec gives
- Using Top2Vec we can find related articles, topics, and keywords with a confidence score. To do this, Top2Vec provides the following outputs:
- A list of topics with their size, keywords, and articles (documents)
- These topics are organized in a hierarchy
- Comparing Top2Vec and BERTopic
- How Top2Vec and BERTopic are similar
- Here’s what we found:
- Pros. Both Top2Vec and BERTopic are similar in many aspects. Both support hierarchical topic reduction, multilingual analysis, unsupervised finding of topics, and use embeddings so no preprocessing of the original data (like stemming and lemmatization) is required.
- Cons. Both also suffer from some similar disadvantages. They can generate many topics (some even outliers with too few related articles) and thus require labor-intensive inspection of each topic. Also both lack objective evaluation of performance.
- How Top2Vec and BERTopic differ
- Here’s what we found:
- Labeling. Both use clustering algorithms like HDBSCAN but BERTopic goes a step further and identifies the topic names of dense semantic space using class-based TF-IDF. This ensures uniqueness across topics.
- Outliers. BERTopic automatically removes outliers. To achieve the same thing with Top2Vec we would have to filter out results below a certain threshold confidence score.
- Search. While both methods support search, Top2Vec supports document search for related articles. To support this in BERTopic, we will need to code more.
- How Top2Vec is better than BERTopic
- Training and testing BERTopic takes significantly longer (20+ hours). In this aspect Top2Vec is much better:
- Training time: Top2Vec was three times faster than BERTopic as it utilizes multi-threaded processing which can significantly boost training performance on multicore machines.
- Testing time: Here too, Top2Vec was more than three times faster: Top2Vec processed a document of 1000 characters in ~300–400 milliseconds while BERTopic took 1.5–2 seconds.
- How to increase accuracy
- There are two ways to increase accuracy of these models:
- Testing out if pretrained embedding models and see if it fits one’s use case.
- Tune hyper-parameters of UMAP and HDBSCAN.
- References
- Related Articles
- Comparison between Top2Vec and BERTopic
- Universal Sentence Encoder
- Libraries
- Usage

0 results
View:
Gallery
Filters
Your search returned 0 results.